SneakPeek: Future-Guided Instructional Streaming Video Generation
Cheeun Hong, German Barquero, Fadime Sener, Markos Georgopoulos, Edgar Schönfeld, Stefan Popov, Yuming Du, Oscar Mañas, and Albert Pumarola
In ArXiv preprint (), 2025
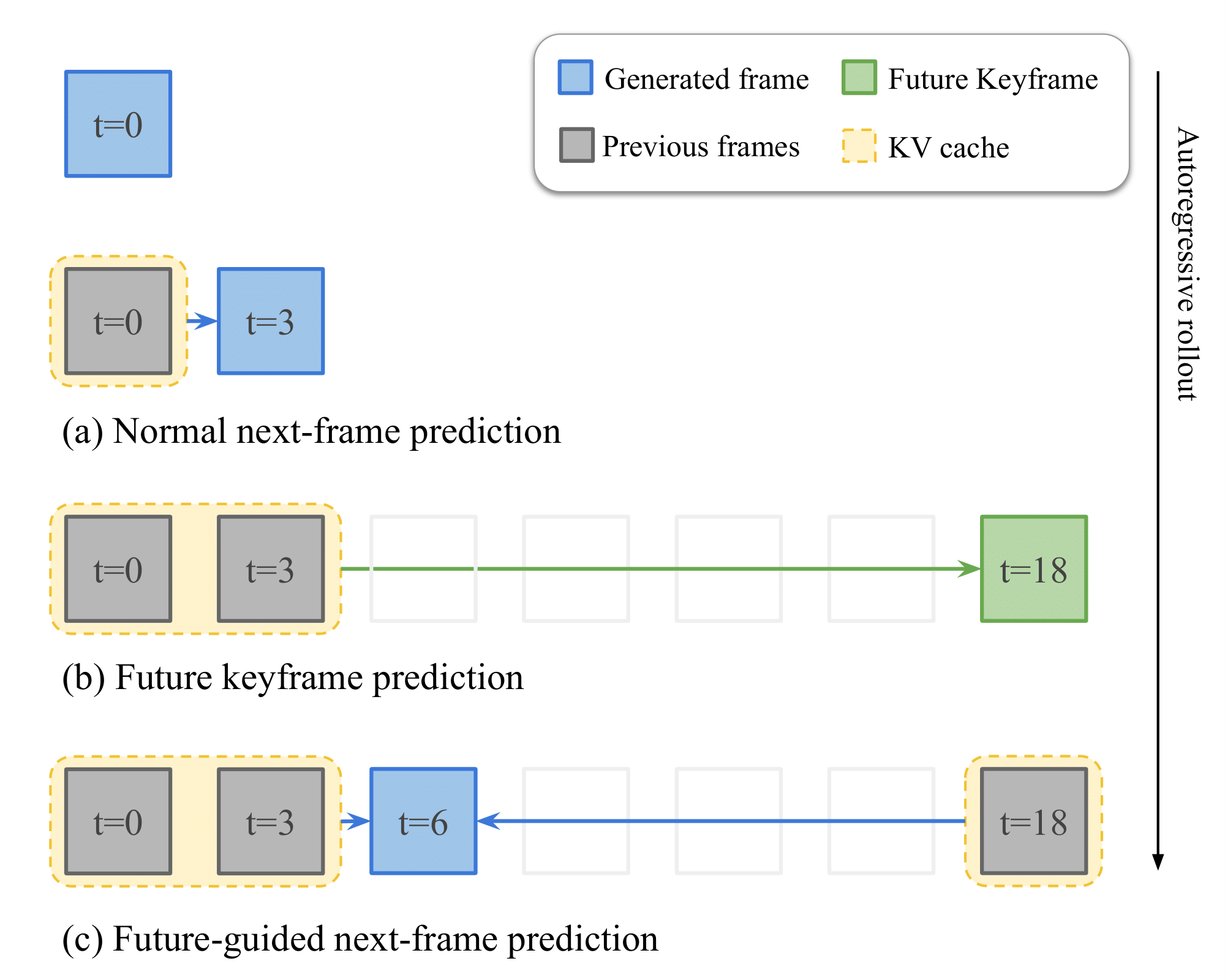
Instructional video generation is an emerging task that aims to synthesize coherent demonstrations of procedural activities from textual descriptions. Such capability has broad implications for content creation, education, and human-AI interaction, yet existing video diffusion models struggle to maintain temporal consistency and controllability across long sequences of multiple action steps. We introduce a pipeline for future-driven streaming instructional video generation, dubbed SneakPeek, a diffusion-based autoregressive framework designed to generate precise, stepwise instructional videos conditioned on an initial image and structured textual prompts. Our approach introduces three key innovations to enhance consistency and controllability: (1) predictive causal adaptation, where a causal model learns to perform next-frame prediction and anticipate future keyframes; (2) future-guided self-forcing with a dual-region KV caching scheme to address the exposure bias issue at inference time; (3) multi-prompt conditioning, which provides fine-grained and procedural control over multi-step instructions. Together, these components mitigate temporal drift, preserve motion consistency, and enable interactive video generation where future prompt updates dynamically influence ongoing streaming video generation. Experimental results demonstrate that our method produces temporally coherent and semantically faithful instructional videos that accurately follow complex, multi-step task descriptions.